
The term OCR has become a common word in today's world of automation and RPA processes.
OCR is nothing more than the digital interpretation of documents from artificial intelligence tools or character recognition. These characters can be handwritten, typed, or machine-encoded text, are scanned by the technology, and then converted.
OCR Types
There are different types of OCR available, let's see the explanation of each one:
- Intelligent Word Recognition: IWR has the ability to identify handwritten or italicized text, with an algorithm that works by recognizing unrestricted handwritten words, rather than selecting individual characters.
- Intelligent Character Recognition: ICR works by identifying a single character at a time and is evolving, making use of built-in machine learning.
- Optical Word Recognition: OCR that works by recognizing typed text for words.
- Optical Character Recognition: It only works by capturing typed text, one character at a time.
- Optical Mark Recognition: A technique of collecting human input data by recognizing marks or patterns on a document.

What is UiPath?
Among the different tools and technologies that have an OCR system is UiPath, which is an instrument for RPA that can be used to automate repetitive tasks, and this means that it limits human interaction. It streamlines processes, brings efficiency and provides insights, making the path to digital transformation fast and profitable. Leverage existing systems to minimize disruption.
UiPath Community vs. UiPath Licensed OCR
UiPath has a free version for any user and a paid version, both have their own OCR system available, and these have slight but important differences between them. Let's take a look at what each of them offers.
UiPath Community
In the community version there is a good and useful OCR but not so powerful and that OCR allows the reading of files with limitations, such as: files with a table, scanned files that are not clear and so on.
Its weakness is noticeable when compared to other more powerful OCR technologies, such as UiPath's Document Understanding, especially for reading documents based on artificial intelligence.
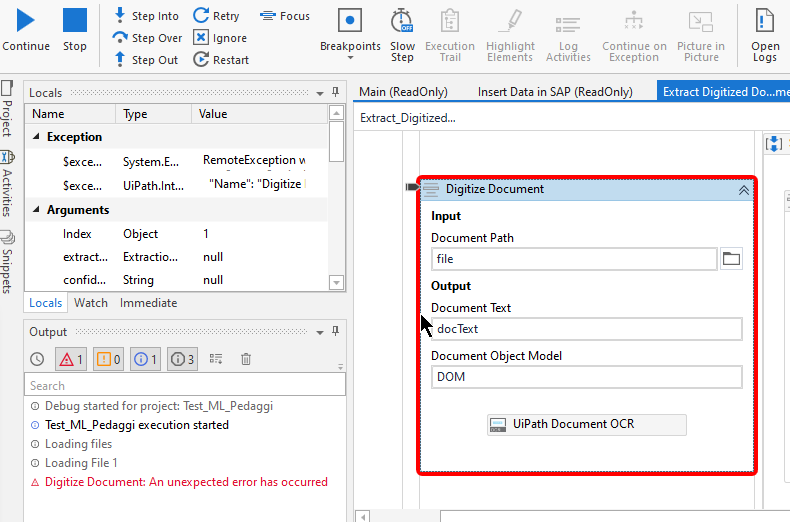
In the default OCR with UiPath you can download free libraries in the community version. It is ideal for reading PDF files with a clear structure.
Its use is basic: it first asks you what you want to read, the OCR is told the data it must obtain from the document, such as address, name, and thus everything necessary is obtained. This free version is powerful, it doesn't have many limitations, but everything will always depend on each file and its complexity.
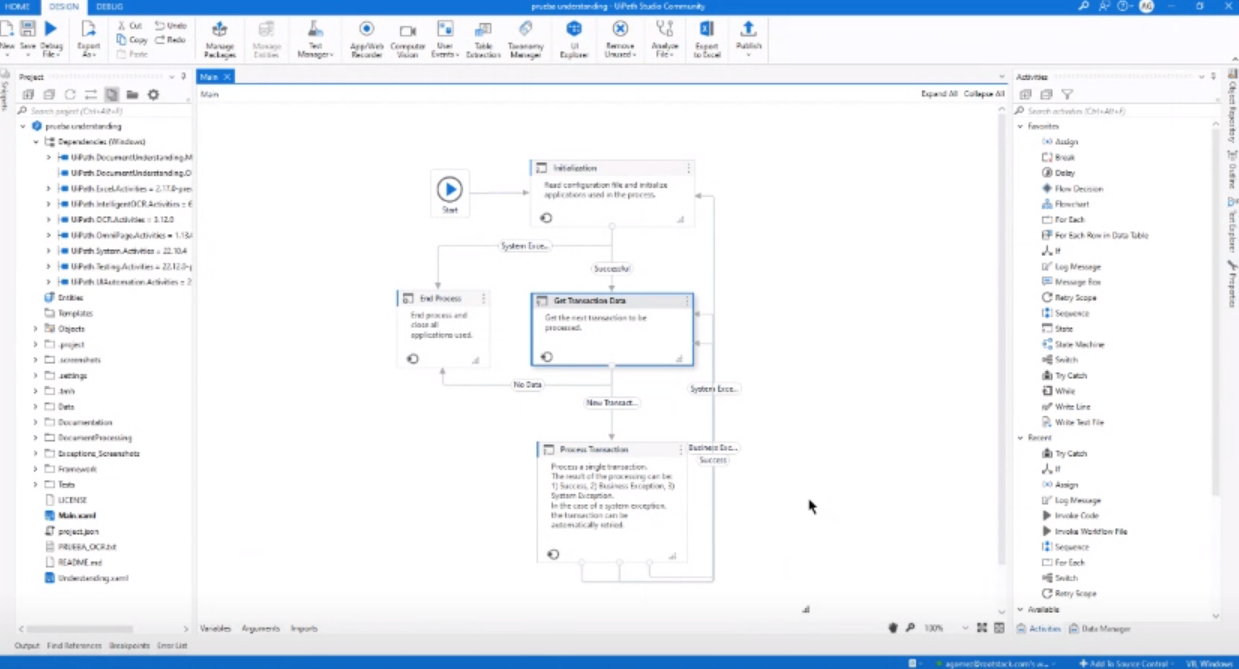
With scanned files, the OCR that comes by default with UiPath also works. It gets the raw and unordered data, so an algorithm would have to be applied to get the ordered information. The positive thing is that it can read scanned files and you don't have to resort to paid versions to carry out this process.
UiPath Community's OCR is quite powerful despite not having all the features that a paid version does. The limitations are not very noticeable, they only come from file reading issues, since this free version can fail when a file is not properly scanned, with blurred handwriting or handwriting by a person.
UiPath Licensed OCR
By having the paid version, UiPath offers an OCR to its users with more power, which has the ability to read documents scanned that are not very clear, written by a person's hand or with complex tables and loose data.
The licensed OCR gives the developer the possibility to "teach" how to read a document with complex tables, for example, those that have a single column with several rows of information, something that in the free version is practically impossible to do and would deserve more work, more time and increases the project budget.
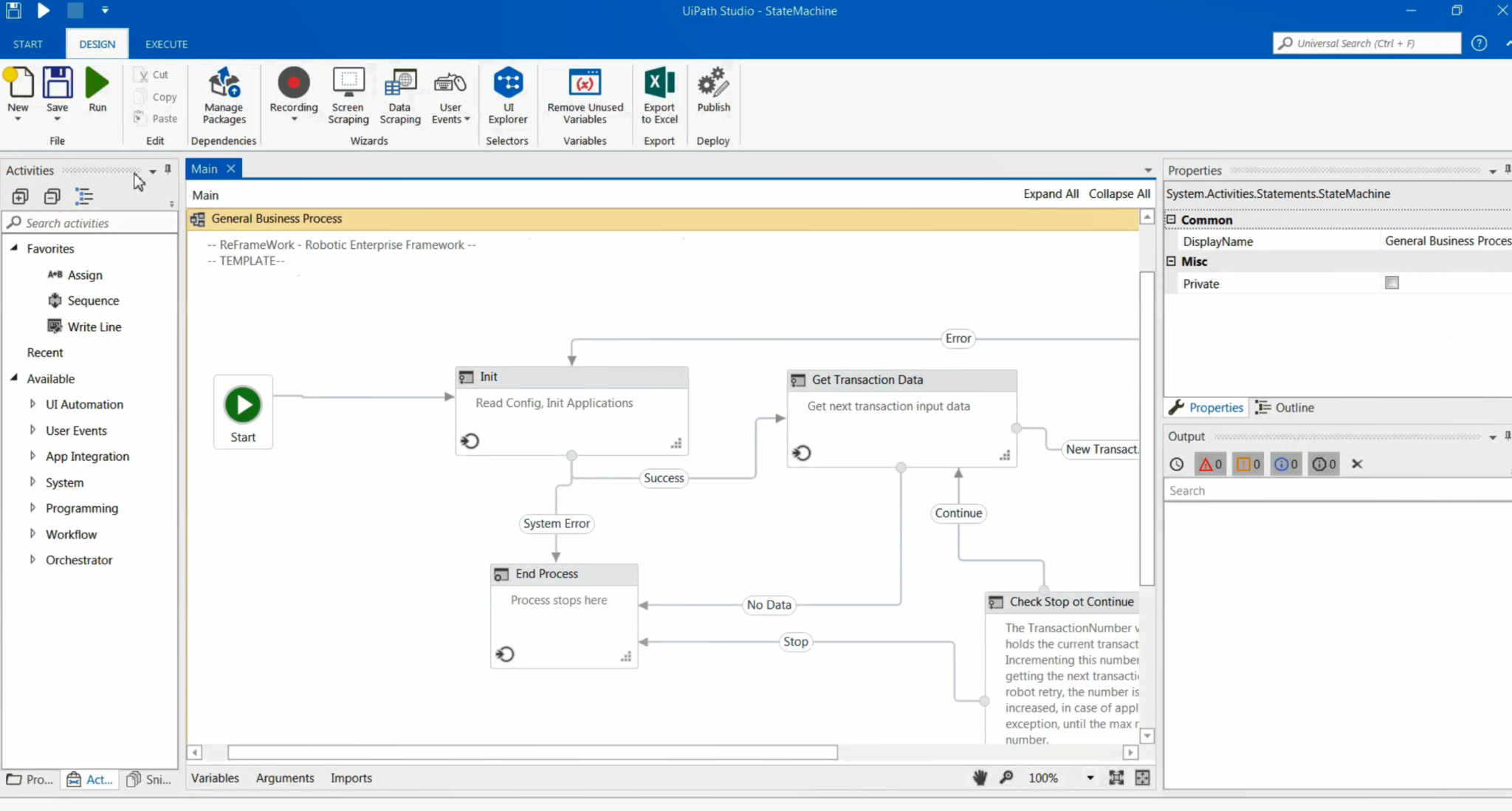
The use of this OCR, which is called Document Understanding, is similar to the free version. There is a process with the same reframe work for either of the two types, only that the paid version comes with exclusive libraries for it, such as: Omnipage, Localserver, Intelligence OCR, which are used to teach robots to read documents.
A positive aspect of having a paid OCR in UiPath is the possibility of having several bots running at the same time on different machines, something that is not possible to do in the free version, there is the possibility of having several bots running, but only on one machine at the same time.
There are companies that need a bot to validate how the technology works and then it is feasible for them to start with the free version in the UiPath Community and later, as they need more bots, they analyze whether a licensed OCR is needed.
The downside of Document Understanding is its rather complex process, unlike the simplicity of the free version. Also, it can be quite expensive, being more budget-friendly to pay for OCR and UiPath-compatible third-party libraries. Also, a third-party tool may already come equipped with all the knowledge to read documents, a process that Document Understanding has to be "taught" how to do.

Does your project need UiPath Community OCR or UiPath Licensed OCR?
In short, the OCR functions that come integrated with UiPath Community are optimal but have several limitations when it comes to reading scanned documents, which are not very clear and have complex structures.
Document Understanding can perform all these activities, but it will require a developer who is an expert in this tool so that they can teach the bot all the necessary steps for each process.
Choosing which one is best for your project is based entirely on your needs and whether they will scale in the future, evolving into complex or low-visibility documents. Rootstack has the teams of experts to help you choose the one that best suits your company.
We recommend you on video

